
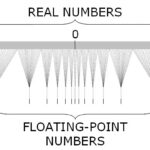
 Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the IEEE Standard for Floating-Point Arithmetic (IEEE 754). IEEE 754 is the standard for all implementations. Hardware also supports storage and operations. Floating point data storage is usually used in numerical calculations. Since the use case is to represent real numbers, the accuracy is a problem. Mathematically there is an infinite amount of other real numbers between two arbitrary chosen real numbers. Computers are notoriously bad at storing an infinite amount of data. For the purposes of programming, this means that all choices for using any floating point data type have to deal with error conditions and how to handle them. Obvious errors include the division by zero. Less obvious conditions are rounding errors, special numbers (infinity, not a number, signed zeroes, subnormal numbers), and overflows.
Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the IEEE Standard for Floating-Point Arithmetic (IEEE 754). IEEE 754 is the standard for all implementations. Hardware also supports storage and operations. Floating point data storage is usually used in numerical calculations. Since the use case is to represent real numbers, the accuracy is a problem. Mathematically there is an infinite amount of other real numbers between two arbitrary chosen real numbers. Computers are notoriously bad at storing an infinite amount of data. For the purposes of programming, this means that all choices for using any floating point data type have to deal with error conditions and how to handle them. Obvious errors include the division by zero. Less obvious conditions are rounding errors, special numbers (infinity, not a number, signed zeroes, subnormal numbers), and overflows.
Not all of the error conditions may pose a threat for your applications. It depends on what type of numerical calculations your code does or consumes. Comparisons have to be implemented in a thoughtful way. Test for equality may fail, because of rounding errors. Using the “real zero” can backfire. The C and C++ standard libraries supply you with a list of constants. Among them is the minimal difference that can be represented in a floating point data type. It is called the epsilon value. Epsilon (ε) is often used to denote very small values. cfloat or float.h defines FLT_EPSILON (for float), DBL_EPSILON (for double), and LDBL_EPSILON (for long double). Using this value as the smallest difference possible is usually a good idea. There is another method for finding neighbouring floating point numbers. C++11 has introduced functions to find the next neighbour value. The accuracy is determined by the unit of least precision (ULP). ULPs are defined by the value of the least significant bit. Using ULPs or the epsilon values is a different approach. ULP checking requires transformation of the values into integer registers. Both methods work well away from the zero. If you are near the zero value, then consider using multiples of the epsilon value as a comparison value.
There is another overlooked fact. The float data type has 32 bit of storage. This means you can use 4 billions different bit combinations, which is not a lot. Looping through all values and stress testing a numerical function can be done in minutes. There is a blog post covering this technique complete with example code.
I have compiled some useful resources for this topic.
 Recently I experimented with
Recently I experimented with