
I have some code that requests URLs, looks for session identifiers or tokens, extracts them, and calculates some indicators of randomness. The tool works, but I decided to add some unit tests in order to play with the Catch2 framework. Unit tests requires some easy to check conditions, so validating HTTP/HTTPS URLs sounds like a good idea to get started. The code uses the curl library for requests, so checking URLs can be done by libcurl or before feeding the URL string to it. Therefore I added some regular expressions. RFC 3986 has a very good description of Uniform Resource Identifiers (URIs). The full regular expression is quite large and match too many variations of URI strings. You can inspect it on the regex101 web site. Shortening the regex to matching URLs beginning with “http” or “https” requires to define what you want to match. Should there be only domain names? Are IP addresses allowed? If so, what about IPv4 and IPv4? Experimenting with the filter variations took a bit of time. The problem was that no regex was matching the pattern. Even patterns that worked fine in other programming languages did not work in the unit test code. The error was hidden in a constructor.
Class definitions in C++ often have multiple variations of constructors. The web interface code can create a default instance where you set the target URL later by using setters. You can also create instances with parameters such as the target or the number of requests. The initialisation code sits in one member function which also initialises the libcurl data structures. So the constructors look like this:
http::http() {
}
http::http( unsigned int nreq ) {
init_data_structures();
set_max_requests( nreq );
return;
}
The function init_data_structures() sets a flag that tells the instance if the libcurl subsystem is working or not. The first constructor does not call the function, so the flag is always false. The missing function call is hard to miss. The reason why the line was missing is that the code had a default constructor at first. The other constructors were added later, and the default constructor function was never used, because the test code never creates instances without an URL. This bring me back to the unit tests. The Catch2 framework does not need a full program code with a main() function. You can directly create instances in your test code snippets and use them. That’s why the error got noticed. Unit tests are not security tests. The missing initialisation function call is most probably not a security weakness, because the code does not run with the web request subsystem flag set to false. It’s still a good way to catch omissions or logic errors. So please do lots of unit tests all of the time.
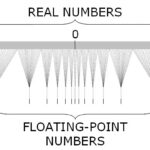 Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the
Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the