
 Learning about programming first and then learning secure coding afterwards is a mistake. Even if you are new to a programming language or its concepts, you need to know what can go wrong. You need to know how to handle errors. You need to do some basic checks of data received, no matter what your toolchain looks like. This is part of the learning process. So instead of learning how to use code constructs or language features twice, take the shortcut and address security and understanding of the concepts at once. An example method of classes and their behaviour. If you think in instances, then you will have to deal with the occasional exception. No one would learn the methods first, ignore all error conditions, and then get back to learn about errors.
Learning about programming first and then learning secure coding afterwards is a mistake. Even if you are new to a programming language or its concepts, you need to know what can go wrong. You need to know how to handle errors. You need to do some basic checks of data received, no matter what your toolchain looks like. This is part of the learning process. So instead of learning how to use code constructs or language features twice, take the shortcut and address security and understanding of the concepts at once. An example method of classes and their behaviour. If you think in instances, then you will have to deal with the occasional exception. No one would learn the methods first, ignore all error conditions, and then get back to learn about errors.
Another example are variables with numerical values. Numbers are notorious. Even the integer data types stay in the Top 25 CWE list since 2019. Integer overflow or underflow simply happens with the standard arithmetic operators. There is no fancy bug involved, just basic counting. You have to implement range checks. There is no way around this. Even Rust requires you to do extra bound checks by using the checked_add() methods. Secure coding always means more code, not less. This starts with basic data types and operators. You can add these logical pitfalls to exercises and examples. By using this approach, you can convey new techniques and how a mind in the security mindset improves the code. There is also the possibility of switching between “normal” exercises and security lessons with a focus on how things go wrong. It’s not helpful to pretend that code won’t run into bugs or security weaknesses. Put the examples of failure and how to deal with it right into your course from the start.
If you don’t know where to start, then consult the secure coding guidelines and top lists of well-known vulnerabilities. Here are some good pointers to get started:
 The words legacy and old carry a negative meaning when used with code or software development. Marketing has ingrained in us the belief that everything new is good and everything old should be replaced to ensure people spend money and time. Let me tell you that this is not the case, and that age is not always a suitable metric. Would you rather have your brain surgery from a surgeon with 20+ years of experience or a freshly graduated surgeon on his or her first day at the hospital?
The words legacy and old carry a negative meaning when used with code or software development. Marketing has ingrained in us the belief that everything new is good and everything old should be replaced to ensure people spend money and time. Let me tell you that this is not the case, and that age is not always a suitable metric. Would you rather have your brain surgery from a surgeon with 20+ years of experience or a freshly graduated surgeon on his or her first day at the hospital?
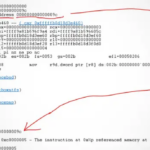 Yesterday the CrowdStrike update disable thousands of servers and clients all across the world. The affected systems crashed when booting. A
Yesterday the CrowdStrike update disable thousands of servers and clients all across the world. The affected systems crashed when booting. A  If all you have is a Large Language Model (LLM), then you will apply it to all of your problems. People are now trying to find 0-days with the might of LLMs. While there is no surprise that this works, there is a better way of pushing your code to the limit. Just use random data! Someone coined the term fuzzing in 1988. People have been using defective punch cards as input for a while longer. With input filtering of data, you want to eliminate as much bias as possible. This is exactly why people create the input data using random data. Human testers think too much, too less, or are too constrained. (Pseudo-)Random number generators rarely have a bias. LLMs do. This means that the publication about finding 0-days by using LLMs should not be good news. Just like human Markov chains, LLMs only „look“ in a specific direction when creating input data. The model is the slave of vectors and the training data. The process might use the source code as an „inspiration“, but so does a compiler with a fuzzing engine. Understanding that LLMs do not possess any cognitive capabilities is the key point here. You cannot ask an LLM what it thinks of the code in combination with certain input data. You are basically using a fancy data generator that uses more energy and is too complex for the task at hand.
If all you have is a Large Language Model (LLM), then you will apply it to all of your problems. People are now trying to find 0-days with the might of LLMs. While there is no surprise that this works, there is a better way of pushing your code to the limit. Just use random data! Someone coined the term fuzzing in 1988. People have been using defective punch cards as input for a while longer. With input filtering of data, you want to eliminate as much bias as possible. This is exactly why people create the input data using random data. Human testers think too much, too less, or are too constrained. (Pseudo-)Random number generators rarely have a bias. LLMs do. This means that the publication about finding 0-days by using LLMs should not be good news. Just like human Markov chains, LLMs only „look“ in a specific direction when creating input data. The model is the slave of vectors and the training data. The process might use the source code as an „inspiration“, but so does a compiler with a fuzzing engine. Understanding that LLMs do not possess any cognitive capabilities is the key point here. You cannot ask an LLM what it thinks of the code in combination with certain input data. You are basically using a fancy data generator that uses more energy and is too complex for the task at hand.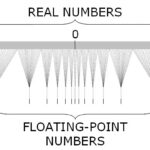 Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the
Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the  Recently I experimented with
Recently I experimented with