
 Testing software and measuring the code coverage is a critical ritual for most software development teams. The more code lines you cover, the better the results. Right? Well, yes, and no. Testing is fine, but you should not get excited about maximising the code coverage. Measuring code coverage can turn into a game and a quest for the highest score. Applying statistics to computer science can show you how many code paths your tests need to cover. Imagine that you have a piece of code containing 32 if()/else() statements. Testing all branches means you will have to run through 4,294,967,296 different combinations. Now add some loops, function calls, and additional if() statements (because 32 comparisons are quite low for a sufficiently big code base). This will increase the paths considerably. Multiply the number by the time needed to complete a test run. This shows that tests are limited by physics and mathematics.
Testing software and measuring the code coverage is a critical ritual for most software development teams. The more code lines you cover, the better the results. Right? Well, yes, and no. Testing is fine, but you should not get excited about maximising the code coverage. Measuring code coverage can turn into a game and a quest for the highest score. Applying statistics to computer science can show you how many code paths your tests need to cover. Imagine that you have a piece of code containing 32 if()/else() statements. Testing all branches means you will have to run through 4,294,967,296 different combinations. Now add some loops, function calls, and additional if() statements (because 32 comparisons are quite low for a sufficiently big code base). This will increase the paths considerably. Multiply the number by the time needed to complete a test run. This shows that tests are limited by physics and mathematics.
Static analysis is a standard tool which helps you detect bugs and problems in your code. Remember that all testing tries to determine the behaviour of your application. Mathematics has more bad news for you. Rice’s Theorem states that all non-trivial semantic properties of a specific code are undecidable. An undecidable problem, which is a decision problem, cannot be solved by any algorithm implementation. Rice published the theorem with a proof in 1951, and it relates to the halting problem. It implies that you cannot decide if an application is correct. You also cannot decide if the code executes without errors. The theorem sounds odd, because clearly you can run code and see if it shows any errors given a specific set of input data. This is a special case. Rice’s theorem is a generalisation and applies to all possible input data. So your successful tests basically work with special cases that do not cause harm. Security testing checks for dangerous behaviour or signs of weaknesses. Increasing the input data variations can cover more cases, but Rice’s theorem still holds, no matter how much effort you put into your testing pipeline.
Let’s get back to the code coverage metric. Of course, you should test all of your code. The major goal for your code is to handle errors correctly, fail safely (i.e. without creating damage), and keep control of the code execution. You can achive these goals with any code coverage per test above 0%. Don’t fall prey to gamification!
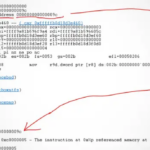 Yesterday the CrowdStrike update disable thousands of servers and clients all across the world. The affected systems crashed when booting. A
Yesterday the CrowdStrike update disable thousands of servers and clients all across the world. The affected systems crashed when booting. A  If all you have is a Large Language Model (LLM), then you will apply it to all of your problems. People are now trying to find 0-days with the might of LLMs. While there is no surprise that this works, there is a better way of pushing your code to the limit. Just use random data! Someone coined the term fuzzing in 1988. People have been using defective punch cards as input for a while longer. With input filtering of data, you want to eliminate as much bias as possible. This is exactly why people create the input data using random data. Human testers think too much, too less, or are too constrained. (Pseudo-)Random number generators rarely have a bias. LLMs do. This means that the publication about finding 0-days by using LLMs should not be good news. Just like human Markov chains, LLMs only „look“ in a specific direction when creating input data. The model is the slave of vectors and the training data. The process might use the source code as an „inspiration“, but so does a compiler with a fuzzing engine. Understanding that LLMs do not possess any cognitive capabilities is the key point here. You cannot ask an LLM what it thinks of the code in combination with certain input data. You are basically using a fancy data generator that uses more energy and is too complex for the task at hand.
If all you have is a Large Language Model (LLM), then you will apply it to all of your problems. People are now trying to find 0-days with the might of LLMs. While there is no surprise that this works, there is a better way of pushing your code to the limit. Just use random data! Someone coined the term fuzzing in 1988. People have been using defective punch cards as input for a while longer. With input filtering of data, you want to eliminate as much bias as possible. This is exactly why people create the input data using random data. Human testers think too much, too less, or are too constrained. (Pseudo-)Random number generators rarely have a bias. LLMs do. This means that the publication about finding 0-days by using LLMs should not be good news. Just like human Markov chains, LLMs only „look“ in a specific direction when creating input data. The model is the slave of vectors and the training data. The process might use the source code as an „inspiration“, but so does a compiler with a fuzzing engine. Understanding that LLMs do not possess any cognitive capabilities is the key point here. You cannot ask an LLM what it thinks of the code in combination with certain input data. You are basically using a fancy data generator that uses more energy and is too complex for the task at hand. Continuous Integration (CI) is a standard in software development. A lot of companies use it for their development process. It basically means using automation tools to test new code more frequently. Instead of continuous, you can also use the word automated, because CI can’t work manually. Modern build systems comprise scripts and descriptive configurations that invoke components of the toolchain in order to produce executable code. Applications build with different programming languages can invoke a lot of tools with individual configurations. The build system is also a part of the code development process. What does this mean for CI in terms of secure coding?
Continuous Integration (CI) is a standard in software development. A lot of companies use it for their development process. It basically means using automation tools to test new code more frequently. Instead of continuous, you can also use the word automated, because CI can’t work manually. Modern build systems comprise scripts and descriptive configurations that invoke components of the toolchain in order to produce executable code. Applications build with different programming languages can invoke a lot of tools with individual configurations. The build system is also a part of the code development process. What does this mean for CI in terms of secure coding?