
Most programmers use floating-point numbers without a second thought. Data types such as float and double are widely available in programming languages. Some languages hide the actual representation and perform conversions in the background. The basis of floating-point variables and how to do operations on them is defined in the IEEE Standard for Floating-Point Arithmetic (IEEE 754) document. It’s worthwhile to learn some basics about what IEEE 754 does for you. It is also important to know that there are special numbers such as +0, -0, infinity, not-a-number, and subnormal numbers. Usually everything just works, but there are special cases where you need to be careful when doing numerical calculations. The division by zero error/exception is a famous example. I want to focus on the subnormal numbers to explain why this kind of numbers were introduced into the standard.
Computing the difference between two numbers can lead to very small numbers. What are the limits of small differences? The C library helps you out by defining the constant FLT_EPSILON (defined in cfloat or float.h). Before IEEE 754 calculations would something lead to 0 when the differences became too small. Subnormal numbers help you out. When enabled, floating-point operations cannot underflow. All absolute differences between two numbers a and b are always positive. This essentially protects you from accidentally dividing by zero. Unless a and b are equal, you are safe. Compilers and processors allow you to disable subnormal numbers. For compilers, there are the -Ofast and -ffast-math flags. It is tempting to use them, but this won’t make your code magically faster. Processors have similar options in the shape of the “flush to zero” (FTZ) and “denormals-are-zero” (DAZ). Intel® has documented FTZ and DAZ. AMD™ and ARM CPUs have the same of similar flags. Enabling FTZ or DAZ sets all subnormal numbers to zero. Why would one want to disable these numbers? Well, subnormal numbers are slower to computer and can affect the performance. This is the reason why -Ofast and -ffast-math set the FTZ/DAZ flags.
Why is this important? It depends a lot of what calculations you do. If you never divide by the difference between two numbers, you are probably fine. The trick is to know if this is the case. You would need to inspect all mathematical operations and track all floating-point variables. There is also a catch. Setting FTZ/DAZ disables subnormal numbers for all code instructions in your process. This includes calling library functions. If components do not expect a change in behaviour regarding floating-point operations, then there can be additional errors or effects. You are not immune if you use a higher-level programming language. There is a blog article where the subnormal number deactivation impacted Python code. There is also an article with a simple example how things can go wrong (examples for C# and C++).
If you are not sure if this affects your code, try running it with and without subnormal numbers. The authors of IEEE 754 recommend not disabling them for very good reasons. I recommend reading the interview with William Kahan about why the proposal for subnormal numbers was added to the standard.
 Testing software and measuring the code coverage is a critical ritual for most software development teams. The more code lines you cover, the better the results. Right? Well, yes, and no. Testing is fine, but you should not get excited about maximising the code coverage. Measuring code coverage can turn into a game and a quest for the highest score. Applying statistics to computer science can show you how many code paths your tests need to cover. Imagine that you have a piece of code containing 32 if()/else() statements. Testing all branches means you will have to run through 4,294,967,296 different combinations. Now add some loops, function calls, and additional if() statements (because 32 comparisons are quite low for a sufficiently big code base). This will increase the paths considerably. Multiply the number by the time needed to complete a test run. This shows that tests are limited by physics and mathematics.
Testing software and measuring the code coverage is a critical ritual for most software development teams. The more code lines you cover, the better the results. Right? Well, yes, and no. Testing is fine, but you should not get excited about maximising the code coverage. Measuring code coverage can turn into a game and a quest for the highest score. Applying statistics to computer science can show you how many code paths your tests need to cover. Imagine that you have a piece of code containing 32 if()/else() statements. Testing all branches means you will have to run through 4,294,967,296 different combinations. Now add some loops, function calls, and additional if() statements (because 32 comparisons are quite low for a sufficiently big code base). This will increase the paths considerably. Multiply the number by the time needed to complete a test run. This shows that tests are limited by physics and mathematics.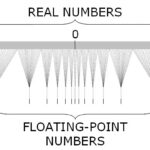 Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the
Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the