
I had an interesting Heisenbug a few days ago. There is a tool that does a lot of XML and JSON document parsing. The code works ok. It is still a prototype. After not using it for a while, I updated the code by recompiling it with a new compiler version. The debug version worked fine. The production version stopped with an illegal instruction (SIGILL). Tracking the cause down required to run the production version with debugger supervision and inspecting the assembler instructions. I was not immediately clear what caused the illegal instruction. The abort occurred at the beginning when the code parses the command-line options. Since there was only the Boost Program Options library involved, there was nothing to see. I saw a list of jumps intersected with undefined instructions. The compiler generated ud1 0x2(%eax),%eax statements on my AMD™ Ryzen 9 (Zen3). This indicated that a run-time protection was the culprit. The production code has some extra compiler flags to add a layer of run-time protection. You can add Clang’s undefined behavior sanitizer to the final binary. Another difference was the compiler option for control flow integrity (CFI) schemes. CFI adds checks to catch undefined behaviour that attackers might abuse. The CFI flag has been in the build file for a long time. It never caused any aborts of the code. Removing the CFI flag also removed the undefined behaviour instructions. This, in turn, made the illegal instruction situation go away.
Control flow integrity is a powerful tool. There are some caveats to consider. CFI can also add checks to header-only libraries. Triggering bugs in components can be unintended. Furthermore, CFI can add seven different schemes to the code (or all of them). It makes sense only to add schemes that actually are useful for your code. You can also disable the undefined instruction abort. You can make the code print a warning with some debug information instead. Make sure to understand the design document published by the Clang developers. CFI is useful for C++ code if you use inheritance and virtual functions. The generated code introduces type checks and will warn you if you combine code that doesn’t fit together.
 Dealing with text is a major task for code. Writing text means to string characters in a row. Characters are the symbols. The encoding determines how these characters are represented in memory. There are single-byte and multi-byte encodings. The
Dealing with text is a major task for code. Writing text means to string characters in a row. Characters are the symbols. The encoding determines how these characters are represented in memory. There are single-byte and multi-byte encodings. The 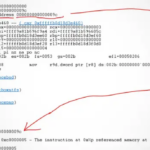 Yesterday the CrowdStrike update disable thousands of servers and clients all across the world. The affected systems crashed when booting. A
Yesterday the CrowdStrike update disable thousands of servers and clients all across the world. The affected systems crashed when booting. A 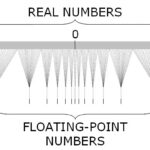 Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the
Floating point data types are available in most programming languages. C++ knows about float, double, and long double data types. Other programming languages feature longer (256 bit) and shorter (16 bit and lower) representations. All data types are specified in the